Bagaimana perusahaan teknologi mengukur dampak AI terhadap pengembangan perangkat lunak
(newsletter.pragmaticengineer.com)- Di tengah adopsi luas alat coding AI dan kenaikan biaya, perusahaan-perusahaan teknologi besar merangkum cara mengukur manfaat nyata AI dengan metrik berlapis
- Kuncinya adalah pendekatan campuran yang melacak bersama metrik dasar engineering yang sudah ada (misalnya throughput PR, change failure rate) dan metrik khusus AI (misalnya tingkat penggunaan AI, penghematan waktu, CSAT)
- Ditekankan pola pikir eksperimental untuk menarik tren dan korelasi melalui penguraian berdasarkan tingkat penggunaan AI per tim/individu/kohort serta perbandingan sebelum dan sesudah
- Diperlukan desain yang seimbang dengan terus memantau kualitas, maintainability, dan pengalaman developer bersama metrik kecepatan untuk mencegah peningkatan utang teknis dan efek balik dari manfaat jangka pendek
- Dalam jangka panjang, pengukuran diperkirakan akan meluas hingga telemetri agent dan area kerja non-coding, dan pada akhirnya pertanyaannya bermuara pada: apakah AI membuat hal-hal yang memang sudah penting—kualitas, kecepatan ke pasar, dan pengalaman developer—menjadi lebih baik?
Wacana dampak AI dan kesenjangan pengukuran
- Seperti yang sering terlihat di LinkedIn dan tempat lain, klaim bahwa AI sedang mengubah cara perusahaan mengembangkan perangkat lunak membanjir
- Laporan terus bermunculan bahwa kode AI dalam skala besar benar-benar dikirim ke production code, seperti Google 25% dan Microsoft 30%
- Sebagian pendiri startup mengklaim AI dapat menggantikan engineer junior, sementara riset METR menunjukkan kemungkinan distorsi persepsi waktu dan penurunan produktivitas
- Media menyederhanakan dampak AI menjadi “seberapa banyak kode yang ditulis”, tetapi akibatnya industri menghadapi risiko akumulasi utang teknis terbesar dalam sejarah
- Meski sudah ada kesepakatan bahwa LOC (lines of code) tidak cocok sebagai metrik produktivitas, metrik ini muncul lagi karena mudah diukur, sehingga nilai yang lebih esensial seperti kualitas, inovasi, kecepatan rilis, dan reliabilitas menjadi tertutupi
- Saat ini banyak pemimpin engineering mengambil keputusan penting terkait alat AI tanpa benar-benar mengetahui apa yang efektif dan apa yang tidak
- Menurut LeadDev’s 2025 AI Impact Report, 60% pemimpin menyebut ‘tidak adanya metrik yang jelas’ sebagai tantangan terbesar
- Para pemimpin di lapangan merasa frustrasi di antara tekanan kinerja dan eksekutif yang terobsesi pada LOC, dan jarak antara informasi yang dibutuhkan dan apa yang benar-benar diukur terus melebar
- Penulis telah meneliti alat developer selama lebih dari 10 tahun, dan sejak 2021 juga memberikan konsultasi tentang peningkatan produktivitas dan pengukuran dampak AI
- Setelah bergabung sebagai CTO DX, ia bekerja sama dengan ratusan perusahaan dan memimpin analisis DevEx, efisiensi, dan dampak AI
- Pada awal 2025, berdasarkan data dari lebih dari 400 perusahaan, ia ikut menulis AI Measurement Framework
- Ini adalah set metrik yang direkomendasikan untuk adopsi AI dan pengukuran dampaknya, dibangun berdasarkan riset lapangan dan analisis data
- Dalam tulisan ini, dibahas cara 18 perusahaan teknologi benar-benar mengukur dampak AI, serta
- contoh metrik nyata dari Google, GitHub, Microsoft, dan lainnya
- cara memanfaatkannya untuk mengetahui apa yang efektif
- metodologi pengukuran dampak AI
- definisi dan panduan metrik dampak AI
1. Metrik nyata yang digunakan 18 perusahaan
- Contoh dari 18 perusahaan seperti Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com, dan Grammarly dibagikan dalam bentuk gambar
- Meski tiap perusahaan mengambil pendekatan berbeda, secara umum mereka berfokus pada beberapa kelompok metrik inti
-
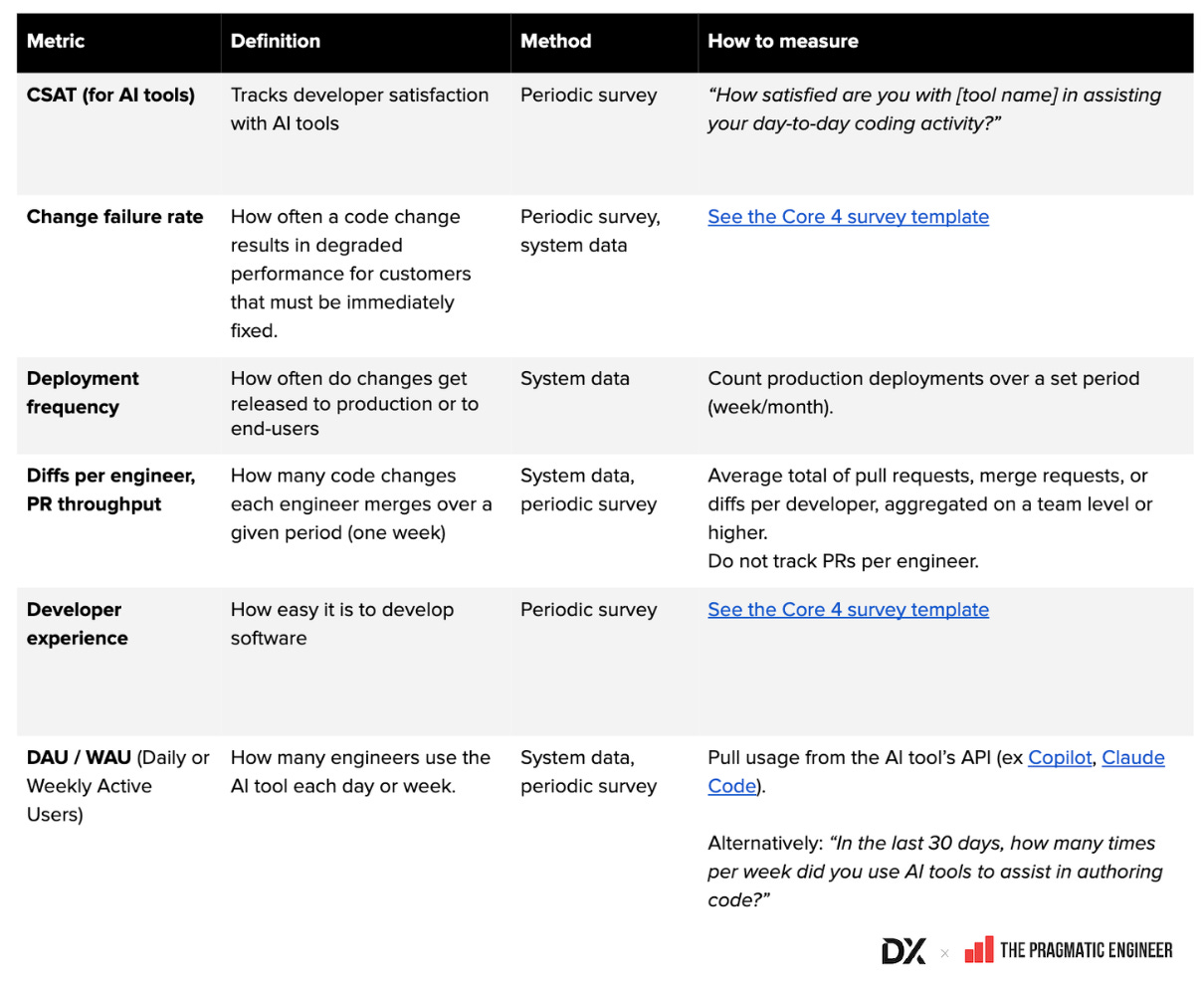
1. Metrik penggunaan (Adoption & Usage)
- DAU/WAU/MAU: hampir semua perusahaan melacak pengguna aktif harian, mingguan, dan bulanan alat AI
- Intensitas penggunaan/peristiwa penggunaan: Google, eBay, dan lainnya merinci hingga penulisan kode, respons chat, dan agentic actions
- CSAT alat AI: banyak perusahaan seperti Dropbox, Webflow, dan Grammarly juga menjalankan survei kepuasan
-
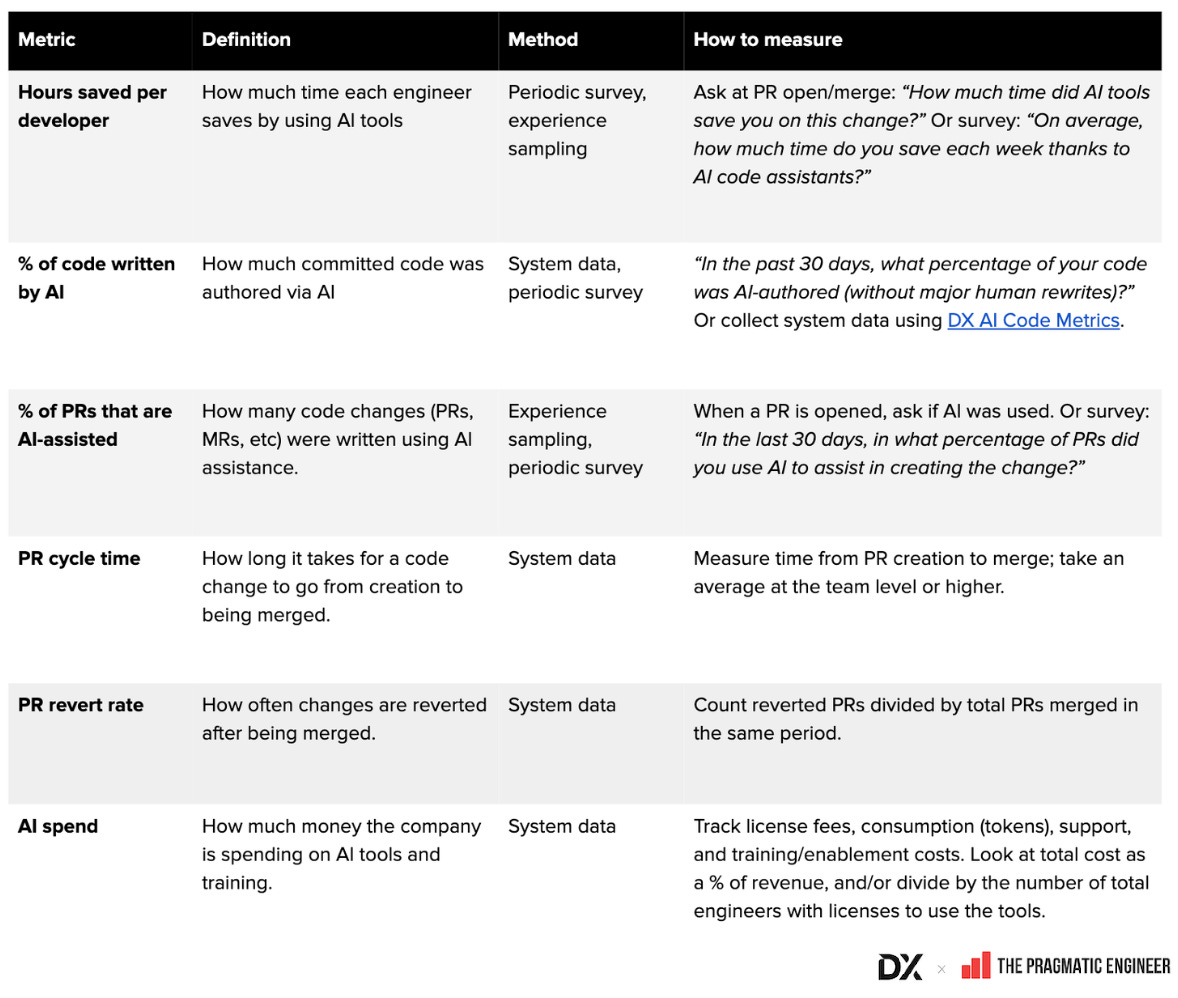
2. Metrik produktivitas (Throughput & Time Savings)
- PR throughput: dilacak secara umum oleh banyak perusahaan seperti GitHub, Dropbox, Webflow, dan CircleCI
- Penghematan waktu (Time savings): mengukur waktu yang dihemat per engineer per minggu (Dropbox, Monzo, Toast, Xero, dan lainnya)
- PR cycle time: digunakan di Microsoft, CircleCI, Xero, Grammarly, dan lainnya
-
3. Metrik kualitas/stabilitas (Quality & Reliability)
- Change Failure Rate: metrik kualitas yang paling umum di GitHub, Dropbox, Adyen, Booking.com, Webflow, dan lainnya
- Maintainability kode/persepsi kualitas: dinilai oleh GitHub, Adyen, CircleCI, dan lainnya dengan keterkaitan ke DevEx
- Bug/rollback rate: Glassdoor (jumlah bug), Toast (PR revert rate)
-
4. Metrik pengalaman developer (Developer Experience)
- Kepuasan developer/survei (DevEx, DXI): digunakan di Atlassian, Webflow, CarGurus, Vanguard, dan lainnya
- Bad Developer Days (BDD): Microsoft secara unik mengukur friksi dengan konsep ‘hari developer yang buruk’
- Beban kognitif·developer friction: Google, eBay, dan lainnya
-
5. Metrik biaya dan investasi (Spend & ROI)
- Pengeluaran AI (total & per developer): beberapa perusahaan melacak biaya, seperti pada kasus Dropbox, Grammarly, dan Shopify
- Capacity worked (tingkat pemanfaatan): Glassdoor mengukur seberapa banyak alat digunakan dibanding potensi maksimumnya
-
6. Metrik inovasi/eksperimen (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow, dan lainnya memetakan kecepatan inovasi sebagai metrik
- Jumlah A/B test: Glassdoor menjadikan jumlah A/B test bulanan sebagai metrik utama
- Metrik hasil seperti penghematan waktu, PR throughput, change failure rate, pengguna yang terlibat, dan tingkat inovasi dilacak bersamaan dengan metrik perilaku penggunaan
- Komposisi metrik berbeda menurut prioritas organisasi dan konteks produk, dan tidak ada satu metrik sakti untuk semua kasus
2. Fondasi yang kokoh: inti pengukuran dampak AI
- Menulis kode dengan AI tidak mengubah standar perangkat lunak yang baik. Kualitas, kemudahan pemeliharaan, dan kecepatan tetap menjadi inti
- Karena itu, metrik yang sudah ada seperti Change Failure Rate, throughput PR, cycle time PR, dan developer experience (DevEx) tetap penting
- Metrik yang sepenuhnya baru tidak diperlukan
- Pertanyaan pentingnya adalah, “Apakah AI membuat hal-hal yang sejak awal penting menjadi lebih baik?”
- Jika hanya berhenti pada metrik permukaan seperti LOC atau acceptance rate, dampak AI tidak bisa dipahami dengan tepat
- Namun, metrik target baru diperlukan untuk memahami secara tepat apa yang terjadi dalam penggunaan AI
- Dengan mengetahui di mana, seberapa banyak, dan dengan cara apa AI digunakan, perusahaan bisa memakainya untuk keputusan terkait anggaran, rollout alat, keamanan, dan compliance
- Metrik AI menunjukkan hal-hal seperti ini:
- Berapa jumlah dan tipe developer yang mengadopsi tool AI?
- Seberapa banyak pekerjaan dan jenis pekerjaan apa yang dipengaruhi AI?
- Berapa biayanya?
- Metrik engineering inti menunjukkan hal-hal seperti ini:
- Apakah tim mengirimkan produk lebih cepat
- Apakah kualitas dan reliabilitas meningkat/menurun
- Apakah kemudahan pemeliharaan kode menurun
- Apakah tool AI mengurangi friksi dalam workflow developer
-
Jika melihat kasus Dropbox
- Metrik AI
- DAU/WAU (pengguna aktif harian dan mingguan)
- CSAT tool AI (kepuasan)
- Penghematan waktu per engineer
- Pengeluaran AI
- Metrik inti (menggunakan Core 4 Framework)
- Change Failure Rate
- Throughput PR
- Hasil
- Pengguna AI rutin mingguan = 90% dari seluruh engineer (lebih tinggi dari rata-rata industri 50%)
- Pengguna AI rutin mencatat kenaikan 20% pada merge PR + penurunan change failure rate
- Yang penting bukan sekadar tingkat adopsi, tetapi memastikan apakah AI benar-benar berkontribusi pada kinerja organisasi, tim, dan individu
- Metrik AI
3. Pemecahan metrik berdasarkan tingkat penggunaan AI
- Berbagai analisis perbandingan dilakukan untuk memahami perubahan yang dibawa AI pada cara kerja developer
- Perbandingan pengguna AI vs non-pengguna
- Perbandingan metrik engineering inti sebelum dan sesudah adopsi tool AI
- Melacak kelompok pengguna yang sama (cohort analysis) untuk mengamati perubahan setelah adopsi AI
- Membagi data secara rinci (slicing & dicing) untuk menemukan pola
- Analisis berdasarkan atribut seperti peran, masa kerja, wilayah, dan bahasa utama
- Contoh: developer junior membuat lebih banyak PR, sementara developer senior melambat karena porsi review meningkat
- Dengan ini, perusahaan bisa mengidentifikasi kelompok yang memerlukan pelatihan dan dukungan tambahan serta kelompok yang mendapat dampak terbesar dari pemanfaatan AI
- Kasus Webflow
- Pada kelompok developer dengan masa kerja 3 tahun atau lebih, efek penghematan waktu dari penggunaan AI adalah yang terbesar
- Saat memakai tool seperti Cursor dan Augment Code, throughput PR meningkat 20% (perbandingan pengguna AI vs non-pengguna)
- Pentingnya baseline yang kuat
- Organisasi yang belum memiliki dasar metrik produktivitas developer akan sulit mengukur dampak AI
- Dengan Core 4 Framework (digunakan oleh Dropbox, Adyen, Booking.com, dll.), baseline bisa dibangun dengan cepat
- Lihat template dan panduan
- Gunakan data sistem, data sampling pengalaman, dan survei berkala bersama-sama untuk melakukan perbandingan yang lebih andal
- Pelacakan berkelanjutan dan pola pikir eksperimental adalah kunci
- Pengukuran satu kali tidak berarti; pelacakan deret waktu diperlukan untuk memahami tren dan pola
- Kesamaan perusahaan yang berhasil: menetapkan tujuan yang spesifik dan menguji hipotesis melalui data
- Tidak bergantung secara membabi buta pada data, tetapi tetap menjaga mindset eksperimen yang berorientasi pada tujuan
4. Kewaspadaan terhadap maintainability, kualitas, dan developer experience
- Pengembangan berbantuan AI masih merupakan area yang baru
- Masih kurang data yang membuktikan dampaknya terhadap kualitas kode dan kemudahan pemeliharaan dalam jangka panjang
- Tantangan utamanya adalah menjaga keseimbangan antara peningkatan kecepatan jangka pendek dan risiko technical debt jangka panjang
- Metrik yang saling mengimbangi harus dilacak bersama
- Sebagian besar perusahaan melacak Change Failure Rate dan throughput PR secara bersamaan
- Jika kecepatan naik tetapi kualitas turun, itu menjadi sinyal masalah yang langsung terlihat
- Metrik tambahan untuk memantau kualitas dan maintainability
- Change confidence: tingkat keyakinan developer terhadap stabilitas kode saat deployment
- Code maintainability: kemudahan memahami dan mengubah kode
- Perception of quality: persepsi developer terhadap kualitas kode dan praktik tim
- Perlu menggabungkan metrik sistem dan metrik self-report
- Data sistem: throughput PR, frekuensi deployment, dll.
- Data self-report: change confidence, maintainability, dll. → sinyal penting untuk mencegah dampak negatif jangka panjang
- Survei developer experience (DevEx) berkala direkomendasikan
- Melalui contoh survei, korelasi antara kualitas, maintainability, dan penggunaan AI bisa dilacak
- Umpan balik tidak terstruktur juga berguna untuk mengidentifikasi masalah yang ada dan membahas solusinya
- Makna nyata dari developer experience (DevEx)
- Bukan konsep benefit seperti “pingpong dan bir”, melainkan menghilangkan friksi di seluruh proses pengembangan
- Tujuannya adalah memastikan efisiensi di seluruh proses perencanaan → pengembangan → pengujian → deployment → operasi
- Tool AI dapat mengurangi friksi dalam penulisan kode dan pengujian, tetapi juga berisiko menambah friksi baru pada review, respons insiden, dan pemeliharaan
- Insight lapangan (Shelly Stuart dari CircleCI)
- Metrik output (throughput PR) menunjukkan apa yang terjadi, tetapi kepuasan developer menunjukkan keberlanjutan
- Adopsi AI dapat menimbulkan ketidaknyamanan di awal, sehingga pelacakan kepuasan menjadi alat penting untuk membedakan friksi jangka pendek vs nilai jangka panjang
- 75% perusahaan juga melacak CSAT/kepuasan terhadap tool AI → fokusnya adalah membangun budaya pengembangan yang berkelanjutan, bukan sekadar kecepatan
5. Metrik yang unik dan tren yang menarik
- Microsoft: Bad Developer Day (BDD)
- Konsep untuk mengukur friksi dan tingkat kelelahan dalam pekerjaan sehari-hari secara real-time
- Faktor yang membuat hari terasa buruk meliputi respons insiden dan penanganan kepatuhan, biaya perpindahan antara rapat dan email, serta waktu yang habis di sistem manajemen kerja
- Diseimbangkan dengan aktivitas PR (indikator proksi waktu coding), sehingga hari dinilai baik jika tetap ada waktu tertentu untuk coding meski ada sebagian pekerjaan bernilai rendah
- Tujuan: memeriksa apakah alat AI mengurangi frekuensi dan tingkat keparahan BDD
- Glassdoor: eksperimen dan pengukuran tingkat pemanfaatan alat
- Melacak apakah AI meningkatkan kecepatan inovasi dan eksperimen melalui jumlah A/B test bulanan
- Juga menjalankan strategi membina power user menjadi evangelis AI internal
- Capacity worked (tingkat pemanfaatan): mengukur penggunaan aktual dibandingkan potensi penggunaan alat untuk menentukan titik kejenuhan adopsi dan keputusan realokasi anggaran
- Penurunan Acceptance Rate
- Dulu merupakan metrik AI utama, tetapi cakupannya sempit karena hanya melihat momen saat saran diterima
- Tidak dapat mencerminkan maintainability, munculnya bug, rollback kode, dan produktivitas yang dirasakan developer
- Kini tidak banyak dipakai sebagai metrik tingkat atas, tetapi ada pengecualian:
- GitHub: digunakan untuk peningkatan Copilot dan pengambilan keputusan produk
- T-Mobile: memperkirakan sejauh mana kode AI benar-benar diterapkan ke production
- Atlassian: digunakan sebagai metrik pendukung untuk kepuasan developer dan kualitas saran
- Analisis biaya dan investasi
- Sebagian besar perusahaan tidak secara agresif melacak biaya penggunaan agar tidak membuat developer enggan memakai alat
- Shopify mengadopsi pendekatan AI Leaderboard yang memberi selamat kepada developer dengan konsumsi token tertinggi
- ICONIQ 2025 State of AI Report: anggaran produktivitas AI di perusahaan pada 2025 diperkirakan meningkat dua kali lipat dibandingkan 2024
- Sebagian beralih dengan cara mengurangi anggaran perekrutan dan mengalokasikannya ulang ke anggaran alat AI
- Ketiadaan telemetri agen
- Saat ini hampir tidak ada pengukuran, tetapi kemungkinan diadopsi dalam 12 bulan ke depan cukup tinggi
- Saat workflow agen otonom makin meluas, kebutuhan untuk mengukur perilaku, akurasi, dan tingkat regresi akan meningkat
- Kurangnya pengukuran aktivitas non-coding
- Saat ini masih terbatas pada dukungan penulisan kode; hal seperti sesi perencanaan dengan ChatGPT atau penanganan issue Jira belum banyak tercakup
- Pada 2026, penggunaan AI diperkirakan meluas ke seluruh tahap SDLC dan pengukurannya juga perlu berkembang
- Aktivitas spesifik seperti code review dan pemeriksaan kerentanan mudah diukur, sedangkan pekerjaan yang abstrak lebih sulit diukur
- Perluasan cakupan pengukuran self-report ("Berapa banyak waktu yang dihemat dengan AI minggu ini?") diperkirakan akan terjadi
6. Bagaimana dampak AI seharusnya diukur?
- AI Measurement Framework
- Dikembangkan bersama Abi Noda, salah satu penulis DevEx Framework
- Disusun berdasarkan data lapangan dari sekitar 400 perusahaan dan riset produktivitas developer selama lebih dari 10 tahun terakhir
- Menggabungkan metrik AI dan metrik inti untuk menilai kecepatan, kualitas, maintainability, dan pengalaman developer (DevEx) secara bersamaan
- Metrik tunggal (misalnya rasio kode yang dihasilkan AI) cocok untuk headline, tetapi bukan alat ukur kinerja yang memadai
- Perlu menggabungkan data kualitatif + kuantitatif
- Pemahaman multidimensi hanya mungkin jika mengumpulkan metrik sistem (throughput PR, DAU/WAU, frekuensi deployment, dan lain-lain) serta metrik self-report (CSAT, penghematan waktu, persepsi maintainability, dan lain-lain)
- Banyak perusahaan menggunakan DX untuk mengumpulkan dan memvisualisasikan data, meski membangun sistem kustom juga memungkinkan
- Metode pengumpulan data
- Data sistem (kuantitatif): API administrasi alat AI (penggunaan, pengeluaran, token, acceptance rate) + metrik SCM, JIRA, CI/CD, build, dan manajemen insiden
- Survei berkala (kualitatif): survei triwulanan/semesteran untuk melihat tren jangka panjang seperti DevEx, kepuasan, kepercayaan terhadap perubahan, dan maintainability yang sulit diperoleh dari metrik sistem
- Experience sampling (kualitatif): menyisipkan pertanyaan singkat di dalam workflow (misalnya tepat setelah mengirim PR, “Apakah Anda menggunakan AI?”, “Apakah kode ini mudah dipahami?”)
- Prioritas eksekusi
- Survei berkala adalah titik mulai tercepat: data awal bisa diperoleh dalam 1–2 minggu
- Seperti tingkat presisi saat memasang tirai berbeda dengan saat meluncurkan roket, keputusan engineering tetap bermakna meski hanya dengan tingkat akurasi yang cukup untuk memberi arah
- Setelah itu, keandalan meningkat jika metode pengumpulan data lain dijalankan bersamaan untuk saling memverifikasi
- Sumber daya tambahan
- Glosarium metrik AI umum (Google Sheet): merangkum definisi, cara perhitungan, dan metode pengumpulan
- Gambar contoh metrik AI dan produktivitas developer
- Hal yang perlu dipertimbangkan saat penerapan internal
- Yang perlu dipastikan bukan mengejar tingkat adopsi atau satu metrik tunggal, melainkan apakah kemampuan untuk mengirimkan software berkualitas tinggi kepada pelanggan dengan cepat benar-benar meningkat
- Pertanyaan kunci:
> “Apakah AI membuat hal-hal yang sudah penting—kualitas, kecepatan rilis, dan pengalaman developer—menjadi lebih baik?” - Pertanyaan yang perlu dibahas dalam rapat kepemimpinan:
- Apa definisi kinerja engineering di organisasi kita?
- Apakah data kinerja sebelum adopsi alat AI sudah tersedia? Jika belum, bagaimana menyiapkan baseline dengan cepat?
- Apakah kita sedang salah mengira aktivitas AI sebagai dampak AI?
- Apakah kita menjaga keseimbangan antara kecepatan, kualitas, dan maintainability?
- Apakah dampaknya terhadap pengalaman developer sudah terlihat?
- Apakah kita menjalankan pendekatan pengukuran berlapis yang mencakup data sistem dan data self-report?
{kind=link}
{kind=link}
7. Cara Monzo mengukur dampak AI
- Tahap awal adopsi
- Alat pertama adalah GitHub Copilot. Karena termasuk dalam lisensi GitHub dan terintegrasi secara natural ke VS Code, semua engineer mulai menggunakannya
- Setelah itu, berbagai alat seperti Cursor, Windsurf, dan Claude Code diuji secara paralel, sambil tetap berinvestasi dengan Copilot sebagai pusatnya
- Filosofi evaluasi alat AI
- Dalam ekosistem alat yang berubah cepat, pengalaman langsung itu wajib
- Performa hanya bisa benar-benar dipahami jika anggota tim menerapkan AI ke kode nyata setiap hari, bahkan sampai membuat dan memakai file konfigurasi agen sendiri
- Evaluasi dilakukan dengan menggabungkan metrik objektif (penggunaan, performa) dan survei subjektif (kepuasan DX)
- Efek dan nilai yang dirasakan
- Para engineer merasa AI memudahkan pencarian dokumentasi, peringkasan, dan pemahaman kode serta mengurangi beban kognitif
- Di pasar talenta yang kompetitif, jika tidak menyediakan alat terbaik, ada risiko kehilangan developer → penyediaan alat itu sendiri menjadi strategi retensi talenta
- Sulitnya pengukuran
- Angka yang disediakan vendor hanya sebatas metrik terbatas seperti tingkat adopsi, sehingga sulit memahami dampak bisnis yang sebenarnya
- Verifikasi yang akurat lewat A/B testing juga pada praktiknya tidak memungkinkan
- Sulit menggabungkan data penggunaan dari berbagai alat (GitHub, Gemini, Slack, Notion, dll.) → keterbatasan telemetri dan vendor lock-in menjadi hambatan utama
- Akibatnya, saat ini pengalaman yang dirasakan developer menjadi sinyal utama
- Area yang bekerja dengan baik
- Hasil besar terlihat pada migrasi: terasa ada pengurangan 40~60% pada pekerjaan perubahan kode
- Pada pekerjaan berulang dan manual seperti penulisan anotasi model data, LLM membuat draf awal, lalu engineer mengoreksinya → penghematan tenaga kerja dalam skala besar
- Pelajaran tak terduga
- Kurangnya kepekaan terhadap biaya LLM: jika melihat tagihan berdasarkan penggunaan token yang nyata, kebutuhan untuk optimasi akan terasa lebih jelas
- Contoh: code review otomatis Copilot memakai banyak token tetapi hasilnya kecil, sehingga secara default dimatikan dan diubah ke model opt-in saat diperlukan
- Area yang tidak menggunakan AI
- Terkait data pelanggan: baik data mentah maupun data yang telah dianonimkan dilarang digunakan dengan AI
- Dalam area data sensitif, pencegahan risiko kebocoran data menjadi prioritas utama
- Filosofi tim platform
- Menyediakan guardrails: menyiapkan lingkungan penggunaan yang aman seperti perlindungan data
- Berbagi kasus: secara transparan membagikan contoh sukses/gagal dan pengalaman penggunaan prompt
- Menekankan dua sisi: menjaga perspektif yang seimbang dengan membagikan sisi positif maupun negatif
- Mengingatkan batasan LLM: AI juga memiliki keterbatasan seperti manusia, sehingga tidak boleh terlalu dipercaya
Kesimpulan dan implikasi
- Pengukuran dampak AI masih merupakan area yang sangat baru
- Belum ada “metodologi terbaik” di industri
- Bahkan perusahaan dengan skala dan pasar yang mirip seperti Microsoft dan Google pun memakai metrik yang berbeda
- Setiap perusahaan memiliki cara dan “flavor” yang unik
- Mengukur metrik yang saling bertentangan secara bersamaan adalah hal yang umum
- Contoh representatif: melacak change failure rate (reliabilitas) dan frekuensi PR (kecepatan) secara bersamaan
- Deploy yang cepat hanya bermakna jika tidak merusak reliabilitas, sehingga kedua sumbu itu perlu diukur secara seimbang
- Mengukur dampak alat AI adalah tantangan yang mirip dengan mengukur produktivitas developer
- Pengukuran produktivitas adalah masalah yang telah dihadapi industri selama lebih dari 10 tahun
- Produktivitas tim tidak bisa dijelaskan dengan satu metrik tunggal, dan mengoptimalkan metrik tertentu tidak berarti produktivitas benar-benar meningkat
- Pada 2023, McKinsey mengumumkan telah “menyelesaikan” metode pengukuran produktivitas, tetapi Kent Beck dan penulis mengambil posisi skeptis terhadap hal tersebut → artikel bantahan
- Belum ada solusi yang jelas, tetapi eksperimen tetap diperlukan
- Sebelum pengukuran produktivitas benar-benar terselesaikan, pengukuran dampak alat AI juga sulit diselesaikan sepenuhnya
- Meski begitu, untuk menjawab pertanyaan “Bagaimana alat coding AI mengubah efisiensi harian/bulanan pada level individu, tim, dan perusahaan?”, eksperimen harus terus dilakukan dan pendekatan baru harus terus dicoba
Belum ada komentar.